
连接InfluxDB数据库
在如何添加数据源中我们已经给大家介绍了添加数据源的步骤,本文主要介绍一下InfluxDB 数据源的具体设置。
1. 连接数据库
在数据源编辑窗口中,在左侧选择“添加新数据”选项卡,然后在弹窗右侧点击数据库分类中的“InfluxDB”选项框。
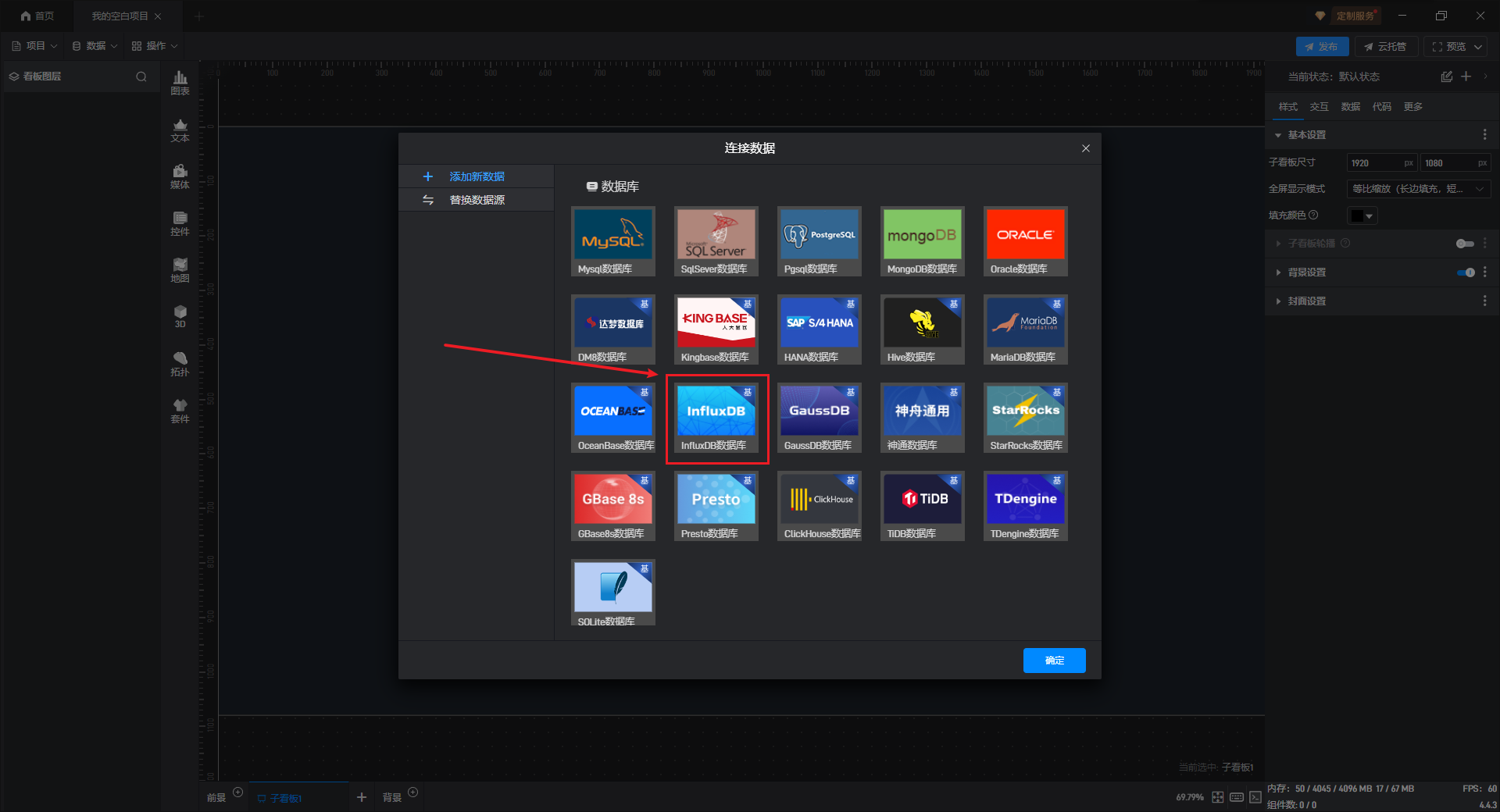
2. 设置参数
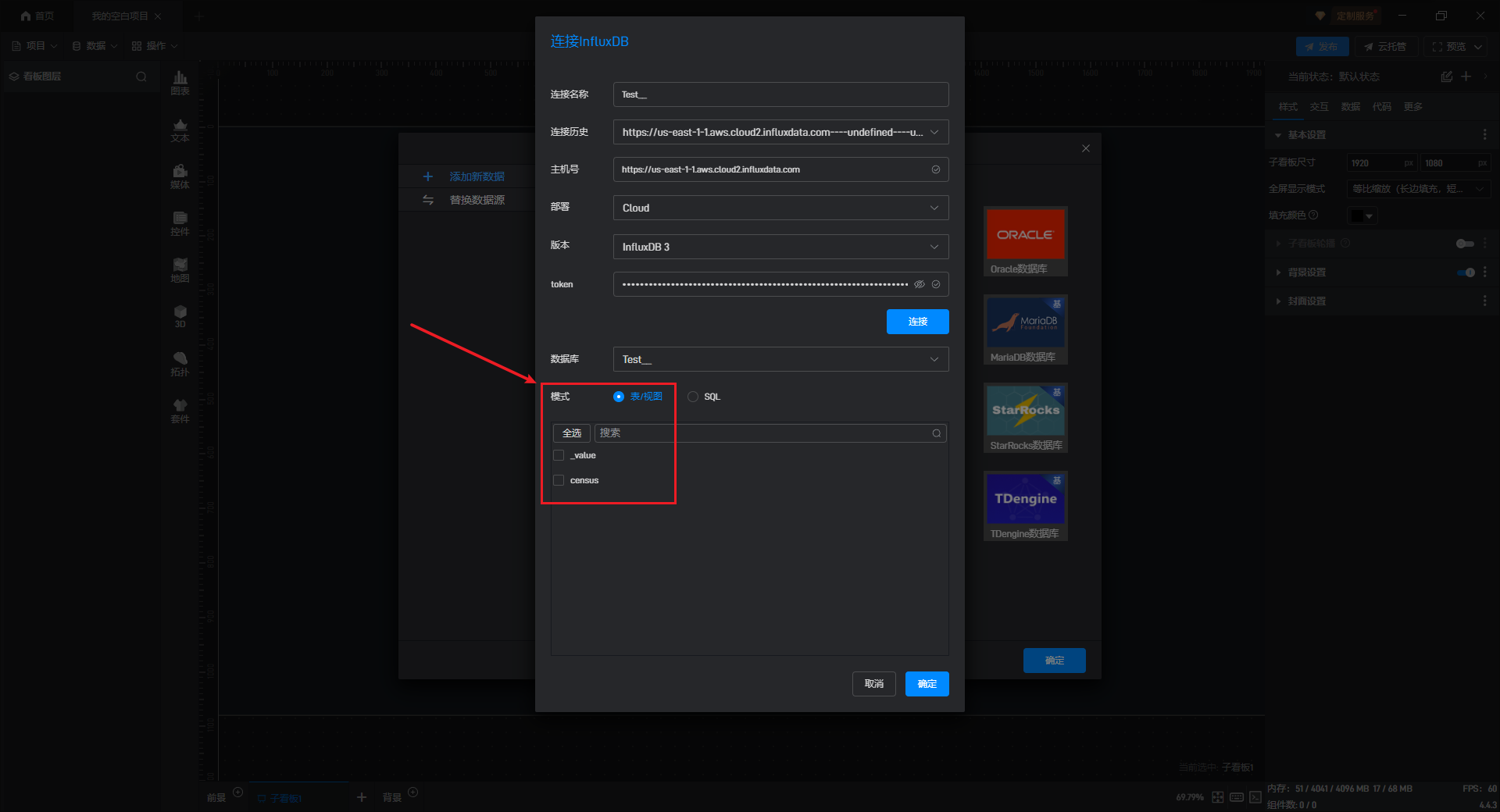
软件会弹出“连接 InfluxDB”的设置框,填入需要连接的数据库基本参数,并点击“连接”按钮。软件会自动尝试连接数据库并获取数据库中所有的表/视图。

3. 查看数据源
添加数据有两种模式:“表/视图”模式和“SQL”模式。
3.1 表/视图模式
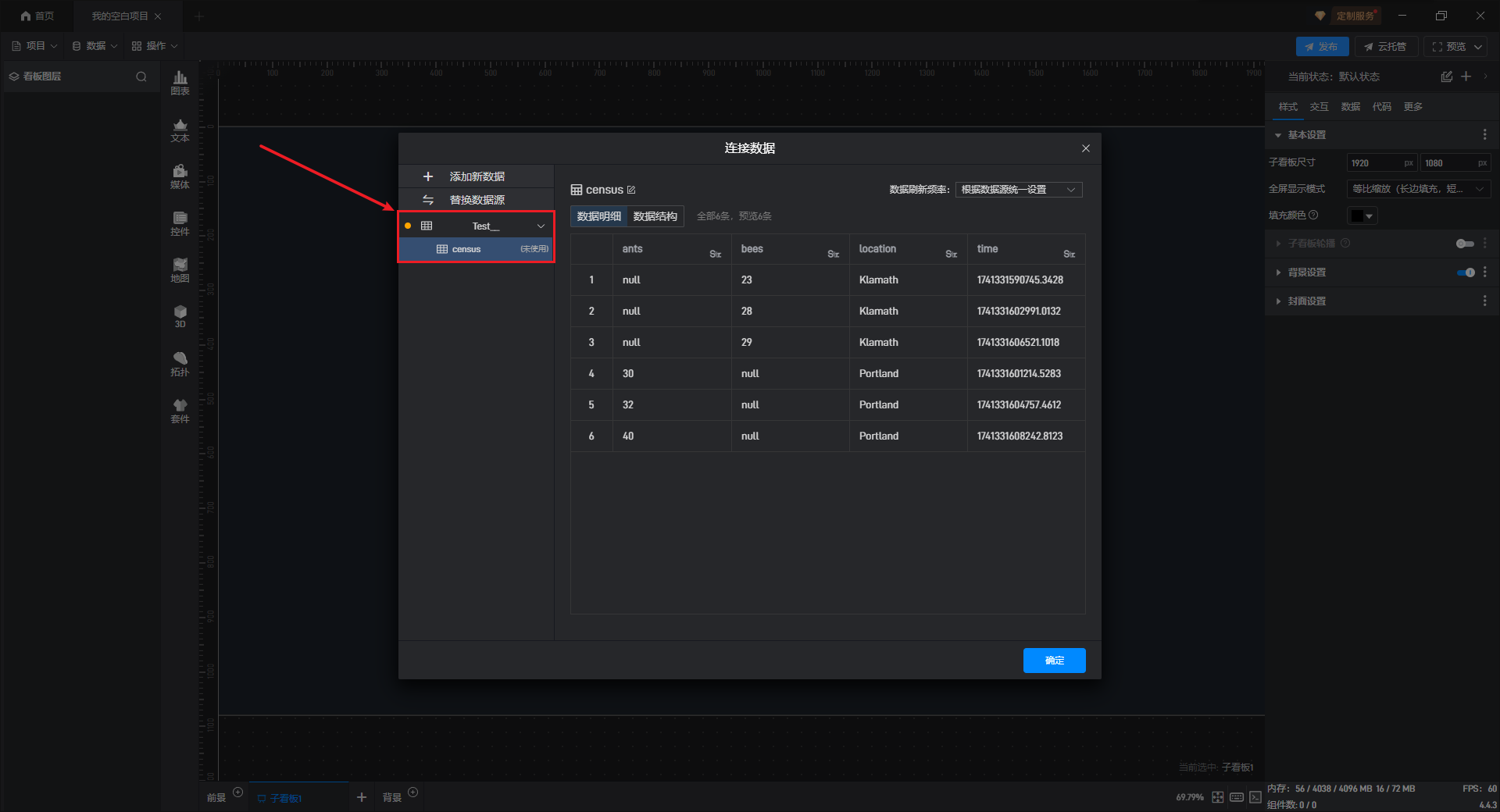
点击“连接”按钮后,在“表/视图”模式下选择需要添加的表所在的数据库名称,软件会在库列表右侧的框中列出该库中所有的表名。勾选需要添加的表,并点击“确定”。
软件会自动加载数据表中的数据并展示在界面中,确认没问题后点击“确定”按钮,一个 InfluxDB 的数据源便添加成功了。
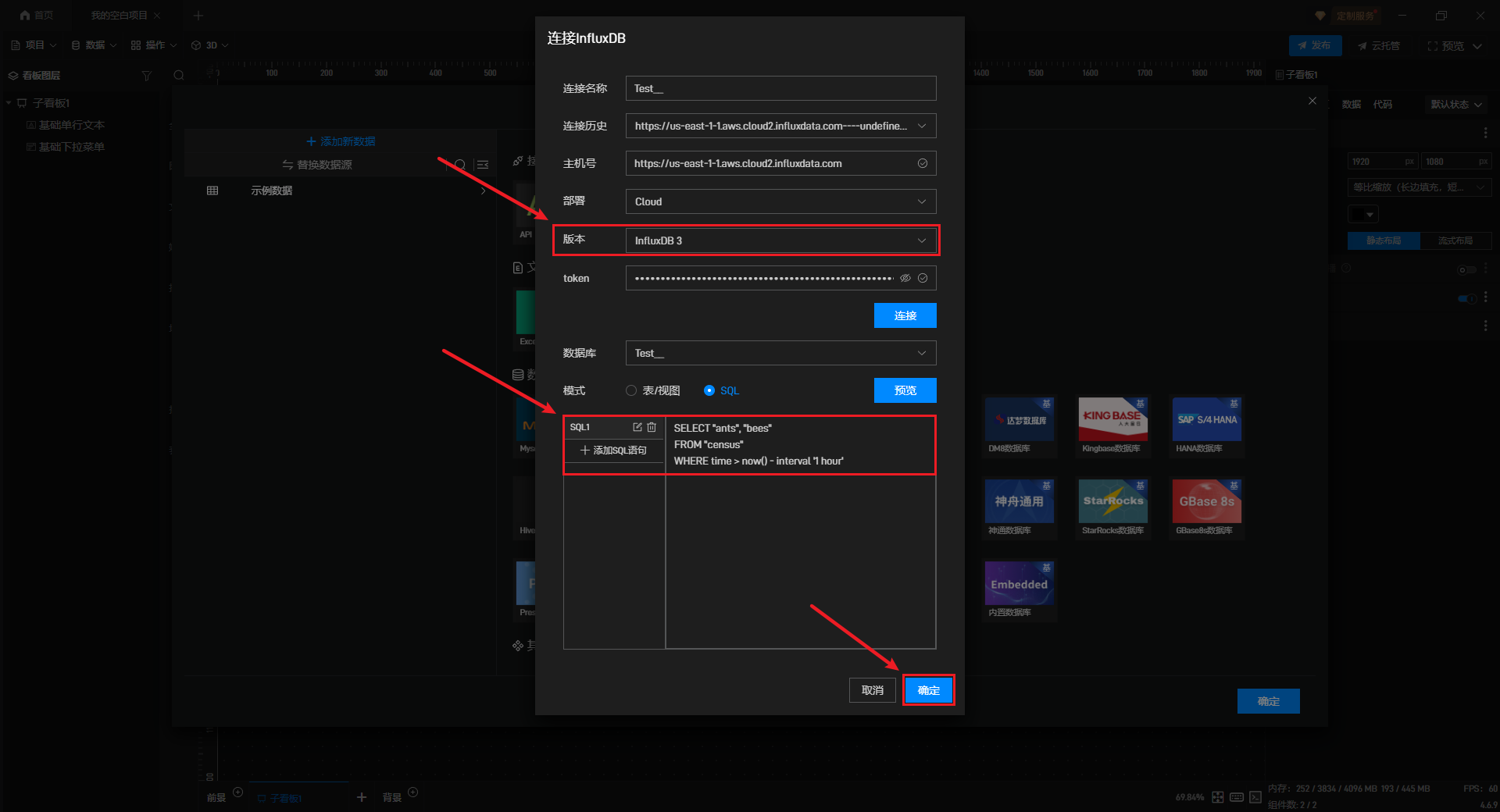
3.2 SQL 模式
在连接数据库时,如果要表进行联合查询、字段筛选、数量筛选、排序等操作时,就可以利用 SQL 语句实现,但 SQL 功能主要适用于开发人员或有一定 SQL 基础的人使用。
例如:我们添加了一个two数据库,想要从two数据库中的census表中筛选出ants字段和bees字段,那么此时只需要添加一个SQL语句就可以实现字段的筛选,以下是具体操作:
1)在InfluxDB 3中,我们可以输入SQL作为查询语句。
点击“连接”按钮后,在“SQL”模式下点击“+添加 SQL 语句”,输入 SQL 语句。
SELECT "ants", "bees"
FROM "census"
WHERE time > now() - interval '1 hour'预览确认无误后,点击“确定”。
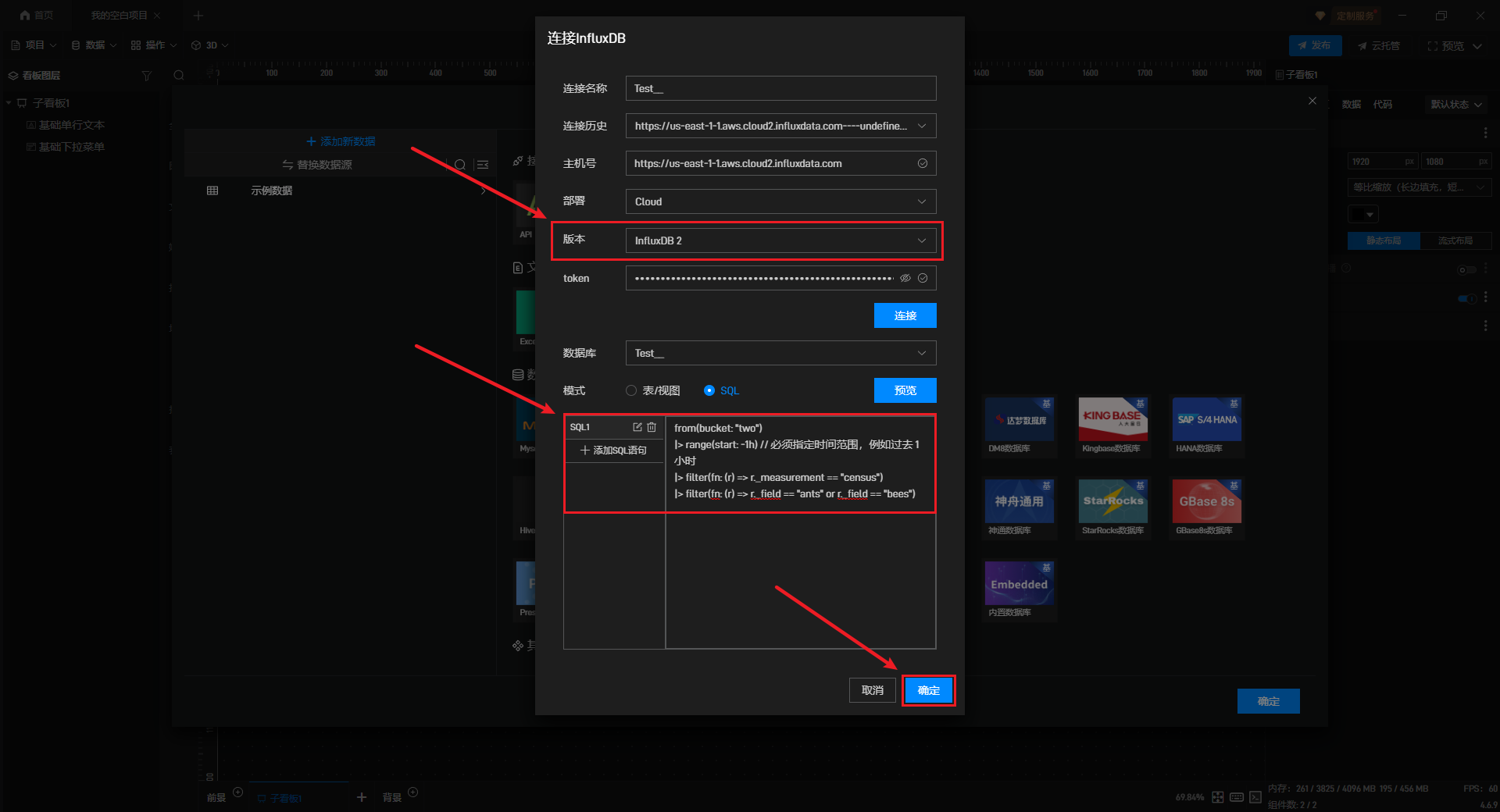
2)在InfluxDB 2中,SQL模式仅支持FLUX语法。
点击“连接”按钮后,在“SQL”模式下点击“+添加 SQL 语句”,输入 SQL 语句。
from(bucket: "two")
|> range(start: -1h) // 必须指定时间范围,例如过去 1 小时
|> filter(fn: (r) => r._measurement == "census")
|> filter(fn: (r) => r._field == "ants" or r._field == "bees")预览确认无误后,点击“确定”。
此时,软件会自动加载数据表中的数据并展示在界面中,确认没问题后点击“确定”按钮,一个InfluxDB的数据源便添加成功了。
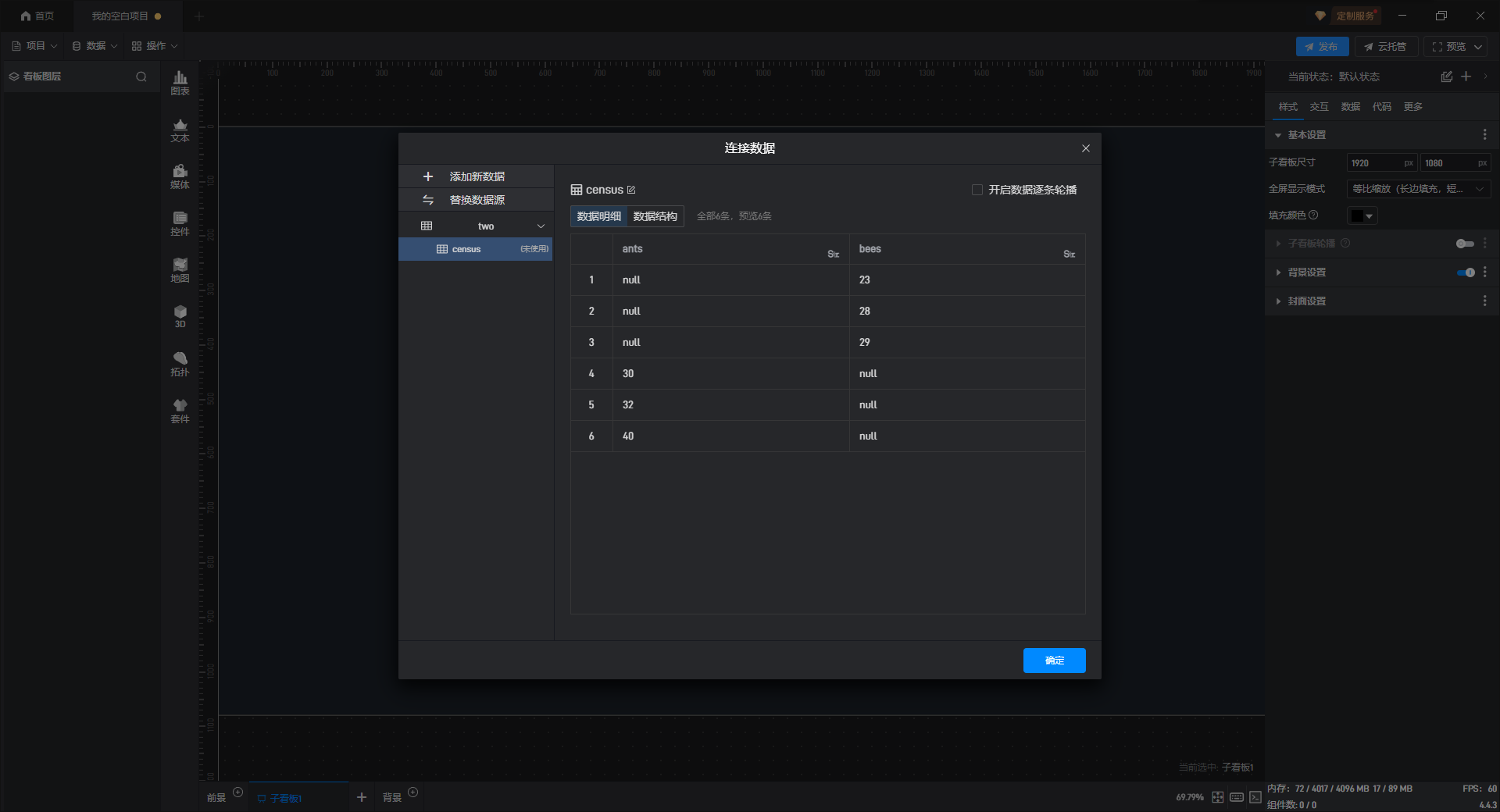
【温馨提示】此处的数据仅支持查看,不支持在线修改,如需修改数据,请直接在数据源文件中修改,修改完成之后请按照相关教程刷新数据。