-
产品
{{ panel.title }}
- 定制服务
-
解决方案
解决方案
建筑与城市
水利水务
工业与农业
智慧党建
车辆与交通
设备运维
Cesium&GIS方案
![]()
智慧社区解决方案
本系统通过数字孪生技术,整合社区各个系统的数据源,将社区运维数据、IoT设备数据与三维城市空间数据相结合,对社区周围环境以及内部物业管理和社区党建等进行了统一管理,从而提升了数据维度,实现了更加直观、更加精细化的社区管理,从而能够全面提升社区管理水平本系统通过数字孪生技术,整合社区各个系统的数据源,将社区运维数据、IoT设备数据与三维城市空间数据相结合,对社区周围环境以及内部物业管理和社区党建等进行了统一管理,从而提升了数据维度,实现了更加直观、更加精细化的社区管理,从而能够全面提升社区管理水平。
![]()
智慧医院解决方案
大屏运用了指标卡、折线图、百分比图等组件,展示了智慧医院资源管理和安防的相关信息,最终得出此智慧医院综合管理平台。
![]()
智慧工厂解决方案
本系统通过数字孪生技术,整合工厂各个系统的数据源,将工厂内部数据、IOT设备数据与工厂三维空间数据相结合,对厂区、厂房、生产线进行统一管理,提升数据维度,实现更加直观、更加精细化的工厂管理,全面提升工厂管理水平。
![]()
智慧医保解决方案
本系统主要面向医保管理部门,通过数字孪生技术, 将二维数据与三维GIS空间数据相结合,不仅可以全面接入现有医保的各项管理数据。
![]()
科技风园区解决方案
高度融合园区多种数据资源,运用3D技术制作园区三维模型,对园区产业、资产、基础设施、能效、安防等领域的关键指标进行综合监测分析,打造智慧园区管理一张图,实现更加高效科学的园区管理,全面提升园区管理水平。
![]()
智慧校园解决方案
通过数字孪生技术,本系统巧妙地整合了校园内各个系统的数据源,将校园运维数据、IOT设备数据与三维校园空间数据相融合,不仅实现了对校园周围环境和内部设施的统一管理,还让校园管理更加直观、精细,为学校带来更先进、高效的管理方式。
![]()
智慧办公园区
此大屏运用了3d室外、折线图、数据表格等组件展示了智慧办公园区管理的实时情况。人员类别统计及车辆实时占用率进行分析。并且通过平均耗电时段及项目信息分析分析。最终得出此智慧办公园区可视化。
![]()
智慧街区
本系统通过数字孪生技术,整合社区各个系统的数据源,将社区运维数据、IoT设备数据与三维城市空间数据相结合,对社区周围环境以及内部物业管理和社区党建等进行了统一管理,从而提升了数据维度,实现了更加直观、更加精细化的社区管理,从而能够全面提升社区管理水平。
![]()
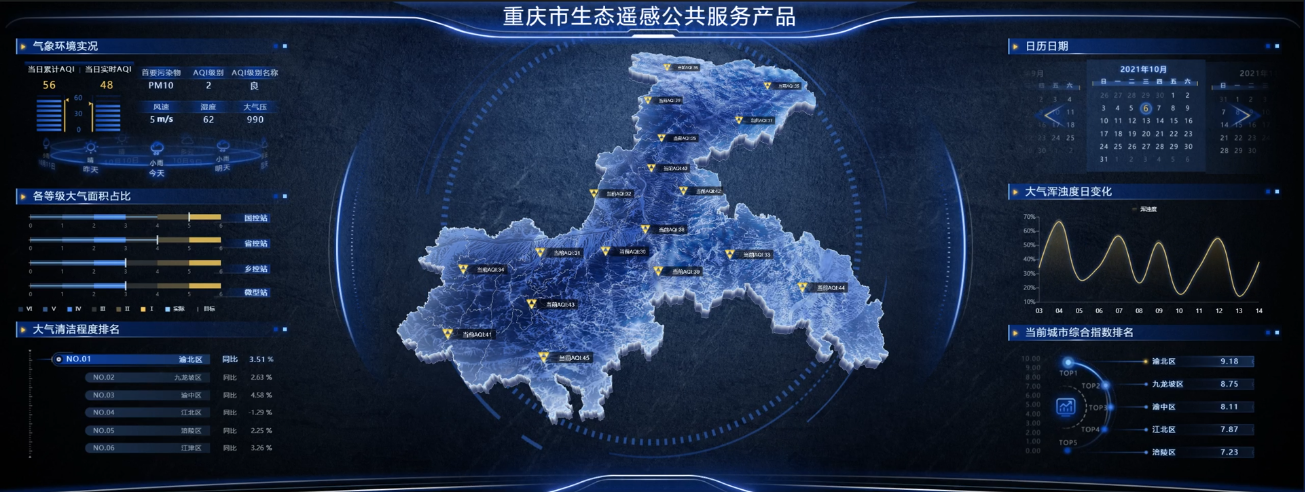
智慧大坝
这是一个关于水闸的模型,展示了水闸全景通过点击标记点来进行交互。
![]()
小流域智慧黄河
GIS结合的方案还原了小流域的真实建筑面貌,该场景支持水流动态监测和控制,换通过三维空间的光影变换,实现数字空间与物理空间的时间映射,从而更加直观的反应出数据的时间和空间属性。
![]()
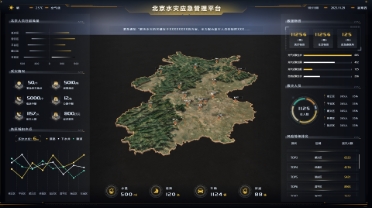
水灾应急管理平台
本大屏使用了北京地图,展示了水灾信息,结合其他的数据可视化组件,适合展示区域性的数据,并且反映了不同区域的水灾情况
![]()
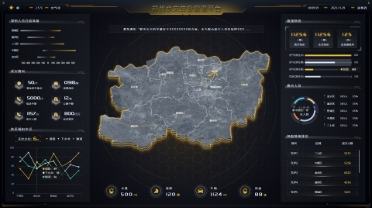
应急管理平台
此大屏运用了分组柱状图、指标卡、数据表格、折线图等组件展示了水闸的建筑设备分布情况,以及水质监测情况。对水质的各项指标以及水位流量的监测总情况进行分析。并且通过对各闸口的设备统计以及实时警报进行分析得出设备监测的一个情况。最终得出此智慧水闸可视化大屏。
![]()
河流污水治理
本大屏使用了相关地图、百分比图、折线图等,结合其他的数据可视化组件,展示了五水共治·河流污水治理大屏的实时数据和整体数据。
![]()
环境卫生数字平台
厦门市环境卫生数据可视化
![]()
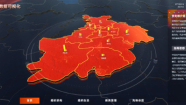
智慧水闸
本大屏使用了省份地图,展示了地图轮回播放信息与飞线相结合的动效,结合其他的数据可视化组件,适合展示区域性的数据,并且反映了不同子区域的数据特征
![]()
智慧工厂解决方案
本系统通过数字孪生技术,整合工厂各个系统的数据源,将工厂内部数据、IOT设备数据与工厂三维空间数据相结合,对厂区、厂房、生产线进行统一管理,提升数据维度,实现更加直观、更加精细化的工厂管理,全面提升工厂管理水平。
![]()
智慧农业解决方案
本系统通过数字孪生技术, 将物联网设备获取到的数据和3D空间渲染相结合,不仅可以直观的观察大棚种植中的常见的指标信息, 而且可以通过大屏管理中的开关对物联网设备进行直接控制,实现一站式的智慧大棚管理。
![]()
智慧矿山解决方案
本系统通过数字孪生技术,整合了矿山各个系统的数据源,将矿山运维数据、IoT设备数据与三维矿山空间数据相结合,对开发区、运输区和储藏区进行了统一管理, 提升了数据维度,实现了更加直观、更加精细化的矿山管理,全面提升了矿山的管理水平。
![]()
工厂生产线
此大屏运用了3D建模还原了工厂内部的真实建筑面貌。
![]()
银行数据中心
这是一个关于银行数据的模板,展示了银行数据,可以通过点击标记点来进行交互。
![]()
智慧工业化养殖系统
本大屏以猪类养殖场为题材,以数据的形式展现工业化养殖系统。本大屏由养殖情况、环境监测、销售交易、监测系统等四个页面组成。其中,养殖情况页面展现的是本养殖区的大概数据,运用到了百分比图、柱状图、表格、环形图、折现图、指标卡等组件。
![]()
智慧港口可视化平台
本大屏使用了城市大师模型地图,在城市大师里添加了植被、车辆等模型,也增加了标记点和视角切换的交互,并结合数据可视化组件,展示有关军港的数据,并且反映了不同港口的情况。
![]()
物流园区可视化平台
本大屏使用了模型地图,展示了物流运输动画,结合其他的数据可视化组件,展示了物流运输的数据。
![]()
智慧党建解决方案
此大屏运用了分组柱状图、指标卡、数据表格、环形图等组件展示了贵阳党组织的信息概览,以及党员基本情况。对人员结构分布以及支部组织总情况进行分析。并且通过对教育管理的概览统计以及先锋示范进行分析得出的一个情况。最终得出此智慧党建数据可视化大屏。
![]()
智慧党建可视化大屏
本大屏使用了轮播图组件,结合其他的数据可视化组件,适合展示党建可视化实时数据和整体数据。
![]()
智慧党建展厅
此大屏运用了分组双轴图、指标卡、数据表格、环形图等组件展示了展厅的信息概览,以及智能监测情况。对人员结构分布以街道组织总情况进行分析。并且通过对党史事迹的概览统计以及组织管理进行分析得出的一个情况。最终得出此智慧党建展厅可视化大屏。
![]()
数字化应急指挥中心
此大屏运用了、指标卡、仪表盘、柱状图等组件展示了数字化改革发展的实时情况,以及指挥情况。对社会管理、经济运行、党政自治、综合法制和数字政府等进行分析。最终得出瑞安市数字化改革发展指挥中心可视化大屏。
![]()
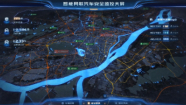
智慧交通解决方案
本系统通过数字孪生技术,将车辆数据和三维GIS空间数据相结合, 不仅可以实时监测车辆各项指标信息及其位置,还可以对突发故障进行实时警报,而且通过提升数据维度, 实现了更加全面、精细化的车辆安全管理,极大地提高了车辆行驶安全水平。
![]()
汽车需求调研互动系统
这是一个关于车辆的模型,并展示了车辆的外观材质部件,可进行更换交互展示。
![]()
杭州市交通运输系统
杭州市交通运输综合展示
![]()
煤矿运输
这是一个关于煤矿运输的模型,并展示了车辆运输过程动画。
![]()
船舶能源管理系统
本大屏是船舶能源管理系统,整体色调为蓝色,运用了条形图、面积图、分组双轴图数据表格等图表,将船舶能源管理数据分为能耗概况、能耗趋势分析、资源节碳情况、船舶情况、各船碳排放、用能区域,也有3D模型图展示。
![]()
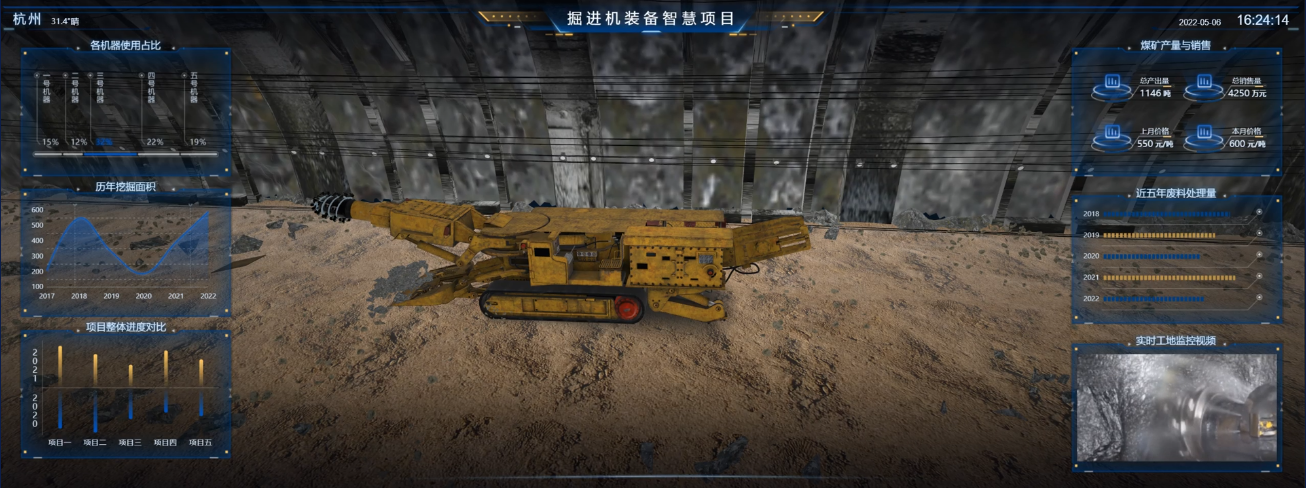
掘进机装备智慧项目
此大屏运用了指标卡、条形图、面积图等组件展示了掘进机项目的实时情况,以及项目进度情况。对机器使用以及挖掘面积进行分析。并且通过对煤矿产量销售以及近五年废料处理量进行分析。最终得出此掘进机装备智慧项目大屏。
![]()
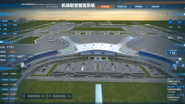
机场智慧管理系统
本大屏以飞机场为主题,展现机场内的总览数据、客运数据、异常数据、安防系统。本大屏中机场总览界面由天气组件、指标卡、环形图、表格组件组成。
![]()
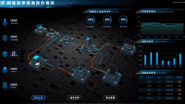
智慧机房解决方案
本系统通过数字孪生技术,整合机房各个系统的数据源,将机房运维数据、IoT设备数据与三维机房空间数据相结合,按照功能划分将机房分为机房001室、机房002室、机房003室、配电房、会议室和消防间等区域并进行了统一管理,提升了数据维度,实现了更加直观、更加精细化的机房运维管理,全面提升了的机房运维水平。
![]()
机房信息数据可视化
机房信息数据可视化
![]()
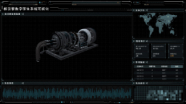
核引擎数字孪生系统
本大屏中心以核引擎模型为展示,整体色调选用了蓝绿色,橘色作为辅助色。内容方面分为“核引擎拆解检测””电流波动““坐标分布”“数据统计”“异常数据”“电压波动”6个板块组成。其中运用了区间柱状图、数据表格、指标卡、日历热力图、3D模型等组件,由此组成此大屏。
![]()
芯调度数据可视化
此大屏运用了指标卡、瀑布图、堆叠柱状图等组件,展示了电商后台实时数据以及消费分析等,最终得出此电商后台管理监测系统可视化大屏。
![]()
工厂运营驾驶舱
此大屏以工厂车间为主题,科技风的模型为主体。大屏整体呈现淡紫色调,营造一种神秘的氛围感,单右侧数据,更多的空间留给模型,展现数据的同时更加突出模型。
![]()
智慧风电可视化
此大屏运用了分组柱状图、指标卡、数据表格、面积图等组件展示了风电的设备分布情况,以及智能监测情况。
![]()
网络信息链路拓扑监控
此大屏运用了3d模型、折线图、数据表格等组件展示了专线宽带趋势。对虚拟机监控及流量监控报警进行分析。并且通过AP流量排行以及磁盘空间使用率。最终得出此网络信息链路拓扑监控。
- 下载
- 素材广场
- 教育版
-
使用教程
- 开发者